
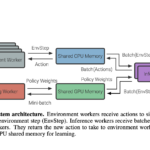
Paper in NeurIPS 2022 on “VER: Scaling On-Policy RL Leads to the Emergence of Navigation in Embodied Rearrangement”
We present Variable Experience Rollout (VER), a technique for efficiently scaling batched on-policy reinforcement learning in heterogenous environments (where different environments take vastly different times to generate rollouts) to many GPUs residing on, potentially, many machines. VER combines the strengths of and blurs the line between synchronous and asynchronous on-policy RL methods (SyncOnRL and AsyncOnRL, respectively). Specifically, it learns from on-policy experience (like SyncOnRL) and has no synchronization points (like AsyncOnRL) enabling high throughput.

Paper in ACM UIST 2022 on “Synthesis-Assisted Video Prototyping From a Document”
Video productions commonly start with a script, especially for talking head videos that feature a speaker narrating to the camera. When the source materials come from a written document — such as a web tutorial, it takes iterations to refine content from a text article to a spoken dialogue, while considering visual compositions in each scene. We propose Doc2Video, a video prototyping approach that converts a document to interactive scripting with a preview of synthetic talking head videos. Our pipeline decomposes a source document into a series of scenes, each automatically creating a synthesized video of a virtual instructor. Designed for a specific domain — programming cookbooks, we apply visual elements from the source document, such as a keyword, a code snippet or a screenshot, in suitable layouts. Users edit narration sentences, break or combine sections, and modify visuals to prototype a video in our Editing UI. We evaluated our pipeline with public programming cookbooks. Feedback from professional creators shows that our method provided a reasonable starting point to engage them in interactive scripting for a narrated instructional video.

Paper in ECCV 2022 on “BLT: Bidirectional Layout Transformer for Controllable Layout Generation”
Creating visual layouts is a critical step in graphic design. Automatic generation of such layouts is essential for scalable and diverse visual designs. To advance conditional layout generation, we introduce BLT, a bidirectional layout transformer. BLT differs from previous work on transformers in adopting non-autoregressive transformers. In training, BLT learns to predict the masked attributes by attending to surrounding attributes in two directions. During inference, BLT first generates a draft layout from the input and then iteratively refines it into a high-quality layout by masking out low-confident attributes. The masks generated in both training and inference are controlled by a new hierarchical sampling policy. We verify the proposed model on six benchmarks of diverse design tasks. Experimental results demonstrate two benefits compared to the state-of-the-art layout transformer models. First, our model empowers layout transformers to fulfill controllable layout generation. Second, it achieves up to 10x speedup in generating a layout at inference time than the layout transformer baseline. Code is released at https://shawnkx.github.io/blt.

Paper in ECCV 2022 on “Improved Masked Image Generation with Token-Critic”
Non-autoregressive generative transformers recently demonstrated impressive image generation performance, and orders of magnitude faster sampling than their autoregressive counterparts. However, optimal parallel sampling from the true joint distribution of visual tokens remains an open challenge. In this paper we introduce Token-Critic, an auxiliary model to guide the sampling of a non-autoregressive generative transformer. Given a masked-and-reconstructed real image, the Token-Critic model is trained to distinguish which visual tokens belong to the original image and which were sampled by the generative transformer. During non-autoregressive iterative sampling, Token-Critic is used to select which tokens to accept and which to reject and resample. Coupled with Token-Critic, a state-of-the-art generative transformer significantly improves its performance, and outperforms recent diffusion models and GANs in terms of the trade-off between generated image quality and diversity, in the challenging class-conditional ImageNet generation.
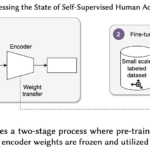
Paper in IMWUT 2022 on “Assessing the State of Self-Supervised Human Activity Recognition using Wearables”
The emergence of self-supervised learning in the field of wearables-based human activity recognition (HAR) has opened up opportunities to tackle the most pressing challenges in the field, namely to exploit unlabeled data to derive reliable recognition systems for scenarios where only small amounts of labeled training samples can be collected. As such, self-supervision, i.e., the paradigm of ‘pretrain-then-finetune’ has the potential to become a strong alternative to the predominant end-to-end training approaches, let alone hand-crafted features for the classic activity recognition chain. Recently a number of contributions have been made that introduced self-supervised learning into the field of HAR, including, Multi-task self-supervision, Masked Reconstruction, CPC, and SimCLR, to name but a few. With the initial success of these methods, the time has come for a systematic inventory and analysis of the potential self-supervised learning has for the field. This paper provides exactly that. We assess the progress of self-supervised HAR research by introducing a framework that performs a multi-faceted exploration of model performance. We organize the framework into three dimensions, each containing three constituent criteria, such that each dimension captures specific aspects of performance, including the robustness to differing source and target conditions, the influence of dataset characteristics, and the feature space characteristics. We utilize this framework to assess seven state-of-the-art self-supervised methods for HAR, leading to the formulation of insights into the properties of these techniques and to establish their value towards learning representations for diverse scenarios.
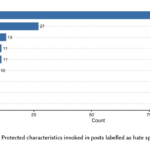
Paper in ICTD 2022 on “Tackling Hate Speech in Low-resource Languages with Context Experts”
Given Myanmar’s historical and socio-political context, hate speech spread on social media have escalated into offline unrest and violence. This paper presents findings from our remote study on the automatic detection of hate speech online in Myanmar. We argue that effectively addressing this problem will require community-based approaches that combine the knowledge of context experts with machine learning tools that can analyze the vast amount of data produced. To this end, we develop a systematic process to facilitate this collaboration covering key aspects of data collection, annotation, and model validation strategies. We highlight challenges in this area stemming from small and imbalanced datasets, the need to balance non-glamorous data work and stakeholder priorities, and closed data sharing practices. Stemming from these findings, we discuss avenues for further work in developing and deploying hate speech detection systems for low-resource languages.

Paper in ICRA 2022 on “Graph-based Cluttered Scene Generation and Interactive Exploration using Deep Reinforcement Learning”
We introduce a novel method to teach a robotic agent to interactively explore cluttered yet structured scenes, such as kitchen pantries and grocery shelves, by leveraging the physical plausibility of the scene. We propose a novel learning framework to train an effective scene exploration policy to discover hidden objects with minimal interactions. First, we define a novel scene grammar to represent structured clutter. Then we train a Graph Neural Network (GNN) based Scene Generation agent using deep reinforcement learning (deep RL), to manipulate this Scene Grammar to create a diverse set of stable scenes, each containing multiple hidden objects. Given such cluttered scenes, we then train a Scene Exploration agent, using deep RL, to uncover hidden objects by interactively rearranging the scene. We show that our learned agents hide and discover significantly more objects than the baselines. We present quantitative results that prove the generalization capabilities of our agents. We also demonstrate sim-to-real transfer by successfully deploying the learned policy on a real UR10 robot to explore real-world cluttered scenes.
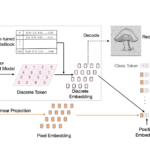
Paper in ICLR 2022 on “Discrete Representations Strengthen Vision Transformer Robustness”
Vision Transformer (ViT) is emerging as the state-of-the-art architecture for image recognition. While recent studies suggest that ViTs are more robust than their convolutional counterparts, our experiments find that ViTs trained on ImageNet are overly reliant on local textures and fail to make adequate use of shape information. ViTs thus have difficulties generalizing to out-of-distribution, real-world data. To address this deficiency, we present a simple and effective architecture modification to ViT’s input layer by adding discrete tokens produced by a vector-quantized encoder. Different from the standard continuous pixel tokens, discrete tokens are invariant under small perturbations and contain less information individually, which promote ViTs to learn global information that is invariant. Experimental results demonstrate that adding discrete representation on four architecture variants strengthens ViT robustness by up to 12% across seven ImageNet robustness benchmarks while maintaining the performance on ImageNet.