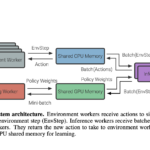
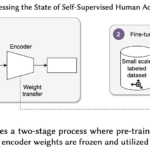
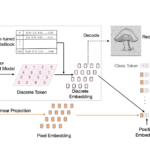
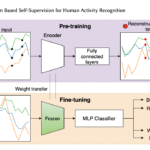
The emergence of self-supervised learning in the field of wearables-based human activity recognition (HAR) has opened up opportunities to tackle the most pressing challenges in the field, namely to exploit unlabeled data to derive reliable recognition systems for scenarios where only small amounts of labeled training samples can be collected. As such, self-supervision, i.e., the paradigm of ‘pretrain-then-finetune’ has the potential to become a strong alternative to the predominant end-to-end training approaches, let alone hand-crafted features for the classic activity recognition chain. Recently a number of contributions have been made that introduced self-supervised learning into the field of HAR, including, Multi-task self-supervision, Masked Reconstruction, CPC, and SimCLR, to name but a few. With the initial success of these methods, the time has come for a systematic inventory and analysis of the potential self-supervised learning has for the field. This paper provides exactly that. We assess the progress of self-supervised HAR research by introducing a framework that performs a multi-faceted exploration of model performance. We organize the framework into three dimensions, each containing three constituent criteria, such that each dimension captures specific aspects of performance, including the robustness to differing source and target conditions, the influence of dataset characteristics, and the feature space characteristics. We utilize this framework to assess seven state-of-the-art self-supervised methods for HAR, leading to the formulation of insights into the properties of these techniques and to establish their value towards learning representations for diverse scenarios.