ECCV


Paper in ECCV 2022 on “BLT: Bidirectional Layout Transformer for Controllable Layout Generation”
Creating visual layouts is a critical step in graphic design. Automatic generation of such layouts is essential for scalable and diverse visual designs. To advance conditional layout generation, we introduce BLT, a bidirectional layout transformer. BLT differs from previous work on transformers in adopting non-autoregressive transformers. In training, BLT learns to predict the masked attributes by attending to surrounding attributes in two directions. During inference, BLT first generates a draft layout from the input and then iteratively refines it into a high-quality layout by masking out low-confident attributes. The masks generated in both training and inference are controlled by a new hierarchical sampling policy. We verify the proposed model on six benchmarks of diverse design tasks. Experimental results demonstrate two benefits compared to the state-of-the-art layout transformer models. First, our model empowers layout transformers to fulfill controllable layout generation. Second, it achieves up to 10x speedup in generating a layout at inference time than the layout transformer baseline. Code is released at https://shawnkx.github.io/blt.

Paper in ECCV 2022 on “Improved Masked Image Generation with Token-Critic”
Non-autoregressive generative transformers recently demonstrated impressive image generation performance, and orders of magnitude faster sampling than their autoregressive counterparts. However, optimal parallel sampling from the true joint distribution of visual tokens remains an open challenge. In this paper we introduce Token-Critic, an auxiliary model to guide the sampling of a non-autoregressive generative transformer. Given a masked-and-reconstructed real image, the Token-Critic model is trained to distinguish which visual tokens belong to the original image and which were sampled by the generative transformer. During non-autoregressive iterative sampling, Token-Critic is used to select which tokens to accept and which to reject and resample. Coupled with Token-Critic, a state-of-the-art generative transformer significantly improves its performance, and outperforms recent diffusion models and GANs in terms of the trade-off between generated image quality and diversity, in the challenging class-conditional ImageNet generation.
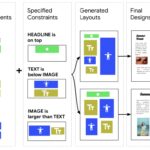
Paper in ECCV 2020 on “Neural Design Network: Graphic Layout Generation with Constraints”
Graphic design is essential for visual communication with layouts being fundamental to composing attractive designs. Layout generation differs from pixel-level image synthesis and is unique in terms of the requirement of mutual relations among the desired components. We propose a method for design layout generation that can satisfy user-specified constraints.
Paper in ECCV Workshop 2012: “Weakly Supervised Learning of Object Segmentations from Web-Scale Videos”
Paper / Citation Abstract We propose to learn pixel-level segmentations of objects from weakly labeled (tagged) internet videos. Espe cially, given a large collection of raw YouTube content, along with potentially noisy tags, our goal is to automatically generate spatiotemporal masks for each object, such as a “dog”, without employing any pre-trained object detectors. We formulate […]