Computer Vision


Award-winning paper in ICML 2024 on “VideoPoet: A large language model for zero-shot video generation.”
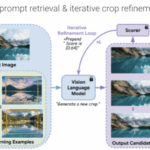
We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs — including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model’s state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet’s ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/

Award-winning paper in ICLR 2023 on “Emergence of Maps in the Memories of Blind Navigation Agents”
Animal navigation research posits that organisms build and maintain internal spatial representations, or maps, of their environment. We ask if machines — specifically, artificial intelligence (AI) navigation agents — also build implicit (or ‘mental’) maps. A positive answer to this question would (a) explain the surprising phenomenon in recent literature of ostensibly map-free neural-networks achieving strong performance, and (b) strengthen the evidence of mapping as a fundamental mechanism for navigation by intelligent embodied agents, whether they be biological or artificial. …

Paper in ICLR 2023 on “Discrete Predictor-Corrector Diffusion Models for Image Synthesis”
We introduce Discrete Predictor-Corrector diffusion models (DPC), extending predictor-corrector samplers in Gaussian diffusion models to the discrete case. Predictor-corrector samplers are a class of samplers for diffusion models, which improve on ancestral samplers by correcting the sampling distribution of intermediate diffusion states using MCMC methods. …

Paper in NeurIPS 2022 on “VER: Scaling On-Policy RL Leads to the Emergence of Navigation in Embodied Rearrangement”
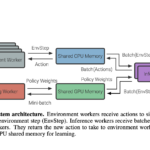
We present Variable Experience Rollout (VER), a technique for efficiently scaling batched on-policy reinforcement learning in heterogenous environments (where different environments take vastly different times to generate rollouts) to many GPUs residing on, potentially, many machines. VER combines the strengths of and blurs the line between synchronous and asynchronous on-policy RL methods (SyncOnRL and AsyncOnRL, respectively). Specifically, it learns from on-policy experience (like SyncOnRL) and has no synchronization points (like AsyncOnRL) enabling high throughput.

Paper in ECCV 2022 on “BLT: Bidirectional Layout Transformer for Controllable Layout Generation”
Creating visual layouts is a critical step in graphic design. Automatic generation of such layouts is essential for scalable and diverse visual designs. To advance conditional layout generation, we introduce BLT, a bidirectional layout transformer. BLT differs from previous work on transformers in adopting non-autoregressive transformers. In training, BLT learns to predict the masked attributes by attending to surrounding attributes in two directions. During inference, BLT first generates a draft layout from the input and then iteratively refines it into a high-quality layout by masking out low-confident attributes. The masks generated in both training and inference are controlled by a new hierarchical sampling policy. We verify the proposed model on six benchmarks of diverse design tasks. Experimental results demonstrate two benefits compared to the state-of-the-art layout transformer models. First, our model empowers layout transformers to fulfill controllable layout generation. Second, it achieves up to 10x speedup in generating a layout at inference time than the layout transformer baseline. Code is released at https://shawnkx.github.io/blt.

Paper in ECCV 2022 on “Improved Masked Image Generation with Token-Critic”
Non-autoregressive generative transformers recently demonstrated impressive image generation performance, and orders of magnitude faster sampling than their autoregressive counterparts. However, optimal parallel sampling from the true joint distribution of visual tokens remains an open challenge. In this paper we introduce Token-Critic, an auxiliary model to guide the sampling of a non-autoregressive generative transformer. Given a masked-and-reconstructed real image, the Token-Critic model is trained to distinguish which visual tokens belong to the original image and which were sampled by the generative transformer. During non-autoregressive iterative sampling, Token-Critic is used to select which tokens to accept and which to reject and resample. Coupled with Token-Critic, a state-of-the-art generative transformer significantly improves its performance, and outperforms recent diffusion models and GANs in terms of the trade-off between generated image quality and diversity, in the challenging class-conditional ImageNet generation.
Paper in ICLR 2022 on “Discrete Representations Strengthen Vision Transformer Robustness”
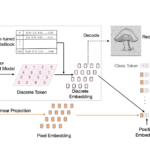
Vision Transformer (ViT) is emerging as the state-of-the-art architecture for image recognition. While recent studies suggest that ViTs are more robust than their convolutional counterparts, our experiments find that ViTs trained on ImageNet are overly reliant on local textures and fail to make adequate use of shape information. ViTs thus have difficulties generalizing to out-of-distribution, real-world data. To address this deficiency, we present a simple and effective architecture modification to ViT’s input layer by adding discrete tokens produced by a vector-quantized encoder. Different from the standard continuous pixel tokens, discrete tokens are invariant under small perturbations and contain less information individually, which promote ViTs to learn global information that is invariant. Experimental results demonstrate that adding discrete representation on four architecture variants strengthens ViT robustness by up to 12% across seven ImageNet robustness benchmarks while maintaining the performance on ImageNet.