Paper in UIST 2023 on “Slide Gestalt: Automatic Structure Extraction in Slide Decks for Non-Visual Access”
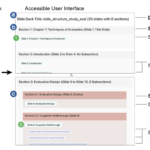
Presentation slides commonly use visual patterns for structural navigation, such as titles, dividers, and build slides. However, screen readers do not capture such intention, making it time-consuming and less accessible for blind and visually impaired (BVI) users to linearly consume slides with repeated content. We present Slide Gestalt, an automatic approach that identifies the hierarchical structure in a slide deck. Slide Gestalt computes the visual and textual correspondences between slides to generate hierarchical groupings. Readers can navigate the slide deck from the higher-level section overview to the lower-level description of a slide group or individual elements interactively with our UI. We derived side consumption and authoring practices from interviews with BVI readers and sighted creators and an analysis of 100 decks. We performed our pipeline with 50 real-world slide decks and a large dataset. Feedback from eight BVI participants showed that Slide Gestalt helped navigate a slide deck by anchoring content more efficiently, compared to using accessible slides.