CVPR 2025 paper on “Cropper: Vision-Language Model for Image Cropping through In-Context Learning”
Cropper: Vision-Language Model for Image Cropping through In-Context Learning Proceedings Article
In: IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2025.
Abstract
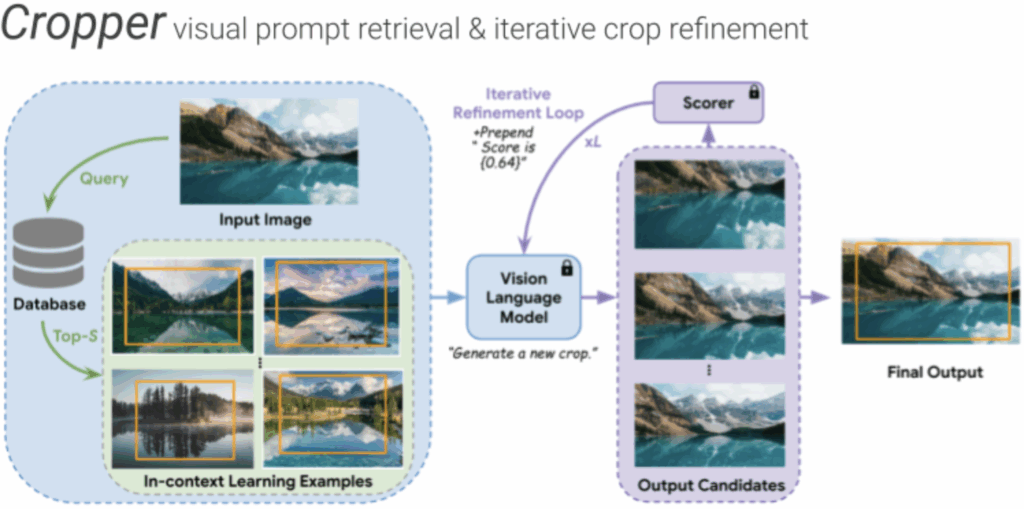
The goal of image cropping is to identify visually appealing crops in an image. Conventional methods are trained on specific datasets and fail to adapt to new requirements. Recent breakthroughs in large vision-language models (VLMs) enable visual in-context learning without explicit training. However, downstream tasks with VLMs remain under explored. In this paper, we propose an effective approach to leverage VLMs for image cropping. First, we propose an efficient prompt retrieval mechanism for image cropping to automate the selection of in-context examples. Second, we introduce an iterative refinement strategy to iteratively enhance the predicted crops. The proposed framework, we refer to as Cropper, is applicable to a wide range of cropping tasks, including free-form cropping, subject-aware cropping, and aspect ratio-aware cropping. Extensive experiments demonstrate that Cropper significantly outperforms state-of-the-art methods across several benchmarks.