Paper in ICTD 2022 on “Tackling Hate Speech in Low-resource Languages with Context Experts”
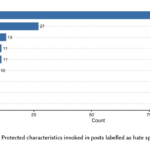
Given Myanmar’s historical and socio-political context, hate speech spread on social media have escalated into offline unrest and violence. This paper presents findings from our remote study on the automatic detection of hate speech online in Myanmar. We argue that effectively addressing this problem will require community-based approaches that combine the knowledge of context experts with machine learning tools that can analyze the vast amount of data produced. To this end, we develop a systematic process to facilitate this collaboration covering key aspects of data collection, annotation, and model validation strategies. We highlight challenges in this area stemming from small and imbalanced datasets, the need to balance non-glamorous data work and stakeholder priorities, and closed data sharing practices. Stemming from these findings, we discuss avenues for further work in developing and deploying hate speech detection systems for low-resource languages.